Tavus, the human computing company building lifelike AI humans that can see, hear, and respond in real time, today launched Phoenix-4, a real-time behavior generation engine that generates emotionally responsive, context-aware human presence in live conversation.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20260218278213/en/
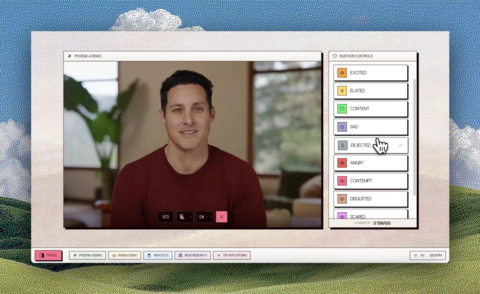
The Phoenix-4 demo interface shows explicit emotion controls, including excited, elated, content, sad, angry, and more, that developers can use to guide AI human emotional expression in real time. Try the demo at phoenix.tavuslabs.org.
Phoenix-4 is the first real-time model to generate and control emotional states, active listening behavior, and continuous facial motion as a single, unified system. It is a full-duplex model that listens and responds simultaneously, generates every pixel from the full head and shoulders down to individual eye blinks, and gives developers explicit control over emotional expression through their LLM and prompts across both speaking and listening states. The model runs at 40fps in 1080p and is available today through the Tavus platform, APIs, PALs, and an updated Stock Replica library with over 40 new replicas.
The Gap in Conversational AI
Despite major advances in voice synthesis, language models, and conversational timing, the visual layer of conversational AI has remained fundamentally behind. In real conversation, humans subconsciously read behavioral signals like eye contact, head movement, pauses, and shifts in expression, and these signals determine whether an interaction builds trust or feels empty.
Most real-time avatar systems fail to model this behavior. They rely on video loops where only lips are generated while hair, eyes, and head pose remain pre-recorded. They treat listening as a static state using pre-recorded loops rather than generated frames, resulting in reverse blinking, random nods, and movements disconnected from conversation context. No real-time avatar model on the market today delivers genuine emotion control. Some systems can trigger a basic expression when text is overtly emotional, but this is not emotion control. Their underlying architectures produce visual artifacts, temporal inconsistencies, and poor identity preservation that prevent the kind of subtle, continuous facial behavior real conversation demands.
Phoenix-4 takes a fundamentally different approach. Rather than animating a face from audio waveforms, it translates speech and conversation context into emotionally grounded facial behavior, teaching machines the art of being human.
The Evolution of Phoenix
Phoenix, Tavus' foundational rendering model first introduced in 2023, is the visual bedrock of the conversational experience. Phoenix-1 made it possible to model avatars in 3D with NeRFs and control them using LLM and TTS models at runtime. Phoenix-2 switched to faster and more powerful 3D Gaussian Splatting, breaking the real-time barrier and enabling Conversational Video Interfaces for the first time. Phoenix-3 expanded generation from mouth and lips to the entire face. Now Phoenix-4 establishes behavioral realism, not just visual realism, as the new standard for conversational AI video.
How Phoenix-4 Works
Phoenix-4 is built on a hybrid Gaussian-diffusion architecture trained on thousands of hours of human conversational data, where a built-in behavioral model learns the relationship between all parts of the face and head to control them implicitly. The pipeline begins with a streaming audio feature extractor that captures both timing and conversational meaning. These features feed into a long-term memory module that analyzes incoming frames alongside past context, producing conditioning signals for the diffusion head. The diffusion head generates plausible motion coefficients using advanced conditioning techniques that allow the model to respond strongly to emotional and audio inputs. These denoised motion coefficients drive a 3D Gaussian Splatting renderer, producing the final image at real-time speed.
A key architectural decision is the use of an implicit motion space, replacing the rigid, predefined expression systems used by other models with a learned latent space trained unsupervised from real emotive data using transformer-based models. This enables the full range of natural facial behavior, including emergent micro-expressions, fluid motion dynamics with no jitter or robotic transitions, and strong identity preservation across long interactions, without the constraints of predefined expression parameters.
Key Capabilities
- Explicit emotion control: Phoenix-4 generates and controls emotional states in real time, with seamless transitions between 10+ emotion states, including happiness, sadness, anger, surprise, disgust, fear, excitement, curiosity, and contentment. You can guide emotional delivery directly through your LLM and prompts, or let the model respond contextually on its own. When paired with Raven-1 for perception, emotion responses become informed by the user’s tone, expression, and intent for even greater accuracy.
- Context-aware active listening: Phoenix-4 generation unlocks active listening, where it reacts to the user and generates visual backchannels. With natural, distinct expression across both talking and listening states, it doesn't just mirror the emotion—it can nod in affirmation, show surprise or concern in reaction to frustration, or express curiosity. Every listening frame is generated rather than looped from pre-recorded footage, meaning no twitching while silent, random nods, weird blinks or other artifacts.
- Seamless transitions: Speaking and listening states transition with no interpolation, no snapping, and no looped footage. Every frame is fully generated, so you don't notice the shift.
- Full headpose and facial control: Head movement, cheeks, eyebrows, lips, forehead, eye gaze, and even eye blinks are all contextually controlled by the model, enabling both subtle micro-expressions and bold macro-expressions while preserving identity.
- Emergent micro-expressions: The model produces natural micro-expressions that emerge from learned representations on vast amounts of real, emotive data, rather than programmed states, enabling a full range of natural facial behavior along with improved lip and facial sync accuracy and significant reduction in visual artifacts.
- Real-time performance in HD: The model runs at 40fps at 1080p, making for high-definition, smooth video that fits right into any video call. Because the model was developed and architected specifically for real time, there is no tradeoff between quality, naturalness or speed.
Why This Matters
Presence, the feeling that someone is genuinely paying attention and responding to what you actually mean, is what separates conversations that build trust from interactions that feel like talking to a screen. Presence emerges not from any single expression or gesture, but from the feeling those behaviors create together. Until now, no real-time model has produced this with the accuracy, timing, and emotional nuance required for a person to feel genuinely understood by an AI system.
The impact is measurable. In healthcare, patients who feel understood are more likely to disclose symptoms honestly and follow treatment plans. In education, learners who sense engagement stay longer and retain more. In sales and support, human-feeling interactions drive higher conversion and stronger loyalty. Phoenix-4 produces the behavioral signals that drive these outcomes: longer conversations, deeper engagement, and higher trust.
Phoenix-4 is powered by Raven-1 for perception and works alongside Sparrow-1 for conversational timing, completing a full behavioral stack for human computing and enabling end-to-end conversational systems that communicate through behavior as well as language.
Availability
Phoenix-4 is available today through the Tavus platform, APIs, PALs, using custom replicas and an updated Stock Replica library with over 40 new replicas. Read the research behind the model in the latest Tavus blog and try the Phoenix-4 demo at phoenix.tavuslabs.org
To learn more, visit https://www.tavus.io
About Tavus
Tavus is a San Francisco-based AI research company pioneering human computing, the next era of computing built around adaptive and emotionally intelligent AI humans. Tavus develops foundational models that enable machines to see, hear, respond, and act in ways that feel natural to people.
In addition to APIs for developers and business, Tavus offers PALs, a consumer platform for AI agents that might become your friend, intern, or both.
Learn more at https://www.tavus.io
View source version on businesswire.com: https://www.businesswire.com/news/home/20260218278213/en/
Phoenix-4 is the first real-time model to generate and control emotional states, active listening behavior, and continuous facial motion as a single, unified system.
Contacts
Leigh Disher
leigh@gmkcommunications.com




